PHP代码审计危险函数
代码执行
eval()
1 | eval( string $code) : mixed |
eval()函数就是将传入的字符串当作 PHP 代码来进行执行。
assert()
PHP 5
1 | assert( mixed $assertion[, string $description] ) : bool |
PHP 7
1 | assert( mixed $assertion[, Throwable $exception] ) : bool |
在PHP 5 中,是一个用于执行的字符串或者用于测试的布尔值。在PHP 7 中,可以是一个返回任何值的表达式,它将被执行结果用于判断断言是否成功。
preg_replace()
此函数执行一个正则表达式的搜索和替换。
1 | mixed preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] ) |
参数说明:
- $pattern: 要搜索的模式,可以是字符串或一个字符串数组。
- $replacement: 用于替换的字符串或字符串数组。
- $subject: 要搜索替换的目标字符串或字符串数组。
- $limit: 可选,对于每个模式用于每个 subject 字符串的最大可替换次数。 默认是-1(无限制)。
- $count: 可选,为替换执行的次数。
create_function()
create_function()用来创建一个匿名函数
1 | create_function( string $args, string $code) : string |
参数
- string $args 声明的函数变量部分
- string $code 要执行的代码
create_function()函数在内部执行eval()函数,所以我们就可以利用这一点,来执行代码。
1 |
|
array_map()
array_map()为数组的每个元素应用回调函数
1 | array_map( callable $callback, array $array1[, array $...] ) : array |
array_map():返回数组,是为 array1 每个元素应用 callback函数之后的数组。callback 函数形参的数量和传给array_map() 数组数量,两者必须一样。
参数
- callback:回调函数,应用到每个数组里的每个元素。
- array1:数组,遍历运行
callback函数。 - …:数组列表,每个都遍历运行
callback函数。
通过array_map()这个函数,来调用用户自定义的函数,而用户这里的回调函数其实就是system函数,那么就相当于我们用system函数来对旧数组进行操作,得到新的数组,那么这个新的数组的结果就是我们想要的命令执行的结果了。
1 |
|
call_user_func()
call_user_func()是把第一个参数作为回调函数调用
1 | call_user_func( callable $callback[, mixed $parameter[, mixed $...]] ) : mixed |
参数
第一个参数callback是被调用的回调函数,其余参数是回调函数的参数。
- callback:即将被调用的回调函数
- parameter:传入回调函数的参数
在前面自定义的函数中加入能执行命令的代码就可以代码执行了。
1 |
|
call_user_func_array()
这个函数名称跟上没什么大的差别,唯一的区别就在于参数的传递上,这个函数是把一个数组作为回调函数的参数
1 | call_user_func_array( callable $callback, array $param_arr) : mixed |
参数
- callback:被调用的回调函数
- param_arr:要被传入回调函数的数组,这个数组需要是索引数组
示例
1 |
|
array_filter()
用回调函数过滤数数组中的单元
1 | array_filter( array $array[, callable $callback[, int $flag = 0]] ) : array |
依次将array数组中的每个值传到callback函数。如果callback函数返回true,则array数组的当前值会被包含在返回的结果数组中。数组的键名保留不变。
参数
- array:要循环的数组
- callback:使用的回调函数。如果没有提供
callback函数,将删除array中所有等值为FALSE的条目。 - flag:决定
callback接收的参数形式
代码示例:
1 |
|
usort()
使用用户自定义的比较函数对数组中的值进行排序
1 | usort( array &$array, callable $value_compare_func) : bool |
参数
- array:输入的数组
- cmp_function:在第一个参数小于、等于或大于第二个参数时,该比较函数必须相应地返回一个小于、等于或大于0的数
代码示例:
1 |
|
usort的参数通过GET传参,第一个参数也就是$_GET[0],随便传入一个数字即可。第二个参数也就是$_GET[1]是我们要调用的函数名称,这里采用的是assert函数。
uasort()
这个跟上一个差不多,区别不是很大。此函数对数组排序并保持索引和单元之间的关联。也就是说你这个排完序之后呢,它原来对应的索引也会相应改变,类似于“绑定”。
1 | uasort( array &$array, callable $value_compare_func) : bool |
参数
- array:输入的数组
- value_compare_func:用户自定义的函数
在排完序之后索引也跟着值的位置变化而变化了。那么代码执行的示例代码其实也和上一个差不多。
代码示例
1 |
|
命令执行
system()
这个函数想必我们都是比较熟悉的,此函数就是执行外部指令,并且显示输出
1 | system( string $command[, int &$return_var] ) : string |
参数
- command:必需。要执行的命令
- return_var:可选。若设置了这个参数,那么命令执行后的返回状态就会被放到这个变量中
示例代码:
1 |
|
exec()
这个其实和上面system函数没有太大区别,都是执行外部程序指令,只不过这个函数多了一个参数,可以让我们把命令执行输出的结果保存到一个数组中。
1 | exec( string $command[, array &$output[, int &$return_var]] ) : string |
参数
- command:必需。要执行的命令
- output:可选。如果设置了此参数,那么命令执行的结果将会保存到此数组。
- return_var:可选。命令执行的返回状态。
示例代码:
1 |
|
shell_exec()
此函数通过shell环境执行命令,并且将完整的输出以字符串的方式返回。如果执行过程中发生错误或者进程不产生输出,那么就返回NULL
1 | shell_exec( string $cmd) : string |
参数
- cmd:要执行的命令
代码示例:
1 |
|
passthru()
执行外部程序并且显示原始输出。既然我们已经有执行命令的函数了,那么这个函数我们什么时候会用到呢?当所执行的Unix命令输出二进制数据,并且需要直接传送到浏览器的时候,需要用此函数来替代exec()或system()函数
1 | passthru( string $command[, int &$return_var] ) : void |
参数
- command:要执行的命令
- return_var:Unix命令的返回状态将被记录到此函数。
代码示例:
1 | 一、 |
pcntl_exec()
在当前进程空间执行指定程序。关键点就在于进程空间,倘若我现在设定一个条件,你只有在某个子进程中才能读取phpinfo,那这个时候,我们就需要用到这个函数了。
1 | pcntl_exec( string $path[, array $args[, array $envs]] ) : void |
参数
- path:path必须时可执行二进制文件路径或在一个文件第一行指定了一个可执行文件路径标头的脚本(比如文件第一行是#!/usr/local/bin/perl的perl脚本)
- args:此参数是一个传递给程序的参数的字符串数组
- envs:环境变量,这个想必大家都很熟悉,只不过这里强调一点,这里传入的是数组,数组格式是 key => value格式的,key代表要传递的环境变量的名称,value代表该环境变量值。
示例代码:
1 | //father |
popen()
此函数使用command参数打开进程文件指针。如果出错,那么该函数就会返回FALSE。
1 | popen(command,mode) |
参数
- command:要执行的命令
- mode:必需。规定连接的模式
- r:只读
- w:只写(打开并清空已有文件或创建一个新文件)
代码示例:
1 |
|
proc_open()
此函数执行一个命令,并且打开用来输入或者输出的文件指针
1 | proc_open( string $cmd, array $descriptorspec, array &$pipes[, string $cwd = NULL[, array $env = NULL[, array $other_options = NULL]]] ) |
此函数其实和popen函数类似,都是执行命令
参数
- cmd:要执行的命令
- descriptorspec:索引数组。数组中的键值表示描述符,元素值表示 PHP 如何将这些描述符传送至子进程。0 表示标准输入(stdin),1 表示标准输出(stdout),2 表示标准错误(stderr)。
- pipes:将被置为索引数组,其中的元素是被执行程序创建的管道对应到PHP这一段的文件指针。
- cwd:要执行命令的初始工作目录。必需是绝对路径。此参数默认使用 NULL(表示当前 PHP 进程的工作目录)
- env。要执行命令所使用的环境变量。此参数默认为 NULL(表示和当前 PHP 进程相同的环境变量)
- other_options:可选。附加选项
- suppress_errors (仅用于 Windows 平台):设置为 TRUE 表示抑制本函数产生的错误。
- bypass_shell (仅用于 Windows 平台):设置为 TRUE 表示绕过 cmd.exe shell。
文件包含
include将会包含语句并执行指定文件
1 | include 'filename'; |
关键点就在于执行指定文件,执行给了我们代码执行的机会。倘若此时我们构造了一个后门文件,需要在目标机器执行进行shell反弹,那么如果代码中有include而且没有进行过滤,那么我们就可以使用该函数来执行我们的后门函数。演示如下。
示例代码(1.php):
1 |
|
示例代码(2.php):
1 |
|
include_once()
include_once与include没有太大区别,唯一的其区别已经在名称中体现了,就是相同的文件只包含一次。其他功能和include_once一样,只是增加对每个文件包含的次数。
require()
require的实现和include功能几乎完全相同,那既然一样为什么还要多一个这样的函数呢?( 我也不知道)
其实两者还是有点区别的,什么区别呢?这么说,如果你包含的文件的代码里面有错误,你觉得会发生什么?是继续执行包含的文件,还是停止执行呢?所以区别就在这里产生了。
require在出错时会导致脚本终止,而include在出错时只是发生警告,脚本还是继续执行。
require_once()
这两者关系和include与include_once的关系是一样的。
文件读取(下载)
file_get_contents()
函数功能是将整个文件读入一个字符串
1 | file_get_contents(path,include_path,context,start,max_length) |
参数
- filename:要读取文件的名称。
- include_path:可选。如果也想在 include_path 中搜索文件,可以设置为1。
- context:可选。规定句柄的位置。
- start:可选。规定文件中开始读取的位置。
- max_length:可选。规定读取的字节数。
代码示例:
1 |
|
fopen()
此函数将打开一个文件或URL,如果 fopen() 失败,它将返回 FALSE 并附带错误信息。我们可以通过在函数名前面添加一个 @ 来隐藏错误输出。
1 | fopen(filename,mode,include_path,context) |
参数
- filename:必需。要打开的文件或URL
- mode:必需。规定访问类型(例如只读,只写,读写方式等,方式的规定和其他语言的规定方式一致)
- include_path:可选。就是你可以指定搜索的路径位置,如果要指定的话,那么该参数要指定为1
- context:可选。规定句柄的环境。
代码示例:
1 |
|
这段代码中其实也包含了fread的用法。因为fread仅仅只是打开一个文件,要想读取还得需要用到fread来读取文件内容。
fread()
这个函数刚才在上个函数中基本已经演示过了,就是读取文件内容。这里代码就不再演示了,简单介绍一下参数和用法。
1 | string fread ( resource $handle , int $length ) |
参数
- handle:文件系统指针,是典型地由
fopen创建的resource。 - length:必需。你要读取的最大字节数。
fgets()
从打开的文件中读取一行
1 | fgets(file,length) |
参数
- file:必需。规定要读取的文件。
- length:可选。规定要读取的字节数。默认是1024字节。
可以看出这个函数和之前的fread区别不是很大,只不过这个读取的是一行。
fgetss()
这个函数跟上个没什么差别,也是从打开的文件中读取去一行,只不过过滤掉了 HTML 和 PHP 标签。
1 | fgetss(file,length,tags) |
参数
- file:必需。要检查的文件。
- length:可选。规定要读取的字节数,默认1024字节。
- tags:可选。哪些标记不去掉。
代码示例:
1 |
|
readfile()
这个函数从名称基本就知道它是干啥的了,读文件用的。此函数将读取一个文件,并写入到输出缓冲中。如果成功,该函数返回从文件中读入的字节数。如果失败,该函数返回 FALSE 并附带错误信息。
1 | readfile(filename,include_path,context) |
参数
- filename:必需。要读取的文件。
- include_path:可选。规定要搜索的路径。
- context:可选。规定文件句柄环境。
代码示例:
1 |
|
file()
把文件读入到一个数组中,数组中每一个元素对应的是文件中的一行,包括换行符。
1 | file(path,include_path,context) |
参数
- path:必需。要读取的文件。
- include_path:可选。可指定搜索路径。
- context:可选。设置句柄环境。
代码示例:
1 |
|
parse_ini_file()
从名称可以看出,这个函数不是读取一个简单的文件。它的功能是解析一个配置文件(ini文件),并以数组的形式返回其中的位置。
1 | parse_ini_file(file,process_sections) |
参数
- file:必需。要读取的ini文件
- process_sections:可选。若为TRUE,则返回一个多维数组,包括了详细信息
代码示例:
1 |
|
show_source()/highlight_file()
这两个函数没什么好说的,想必大家也经常见到这两个函数,其作用就是让php代码显示在页面上。这两个没有任何区别,show_source其实就是highlight_file的别名。
文件上传
move_uploaded_file()
此函数是将上传的文件移动到新位置。
1 | move_uploaded_file(file,newloc) |
参数
- file:必需。规定要移动的文件。
- newloc:必需。规定文件的新位置。
代码示例:
1 | $fileName = $_SERVER['DOCUMENT_ROOT'].'/uploads/'.$_FILES['file']['name']; |
这段代码就是直接接收上传的文件,没有进行任何的过滤,那么当我们上传getshell的后门时,就可以直接获取权限,可见这个函数是不能乱用的,即便要用也要将过滤规则完善好,防止上传不合法文件。
文件删除
unlink()
此函数用来删除文件。成功返回 TURE ,失败返回 FALSE。
1 | unlink(filename,context) |
参数
- filename:必需。要删除的文件。
- context:可选。句柄环境。
我们知道,一些网站是有删除功能的。比如常见的论坛网站,是有删除评论或者文章功能的。倘若网站没有对删除处做限制,那么就可能会导致任意文件删除(甚至删除网站源码)。
代码示例:
1 |
|
session_destroy()
在了解这个函数之前,我们需要先了解 PHP session。 PHP session 变量用于存储关于用户会话的信息。关于 sesson 的机制这里我就不再过于详细介绍。
session_destroy()函数用来销毁一个会话中的全部数据,但并不会重置当前会话所关联的全局变量,同时也不会重置会话 cookie
变量覆盖
extract()
此函数从数组中将变量导入到当前的符号表。其实作用就是给变量重新赋值,从而达到变量覆盖的作用。
1 | extract(array,extract_rules,prefix) |
参数
- array:必需。规定要使用的数组。
- extract_rules:可选。extract函数将检查每个键名是否为合法的变量名,同时也检查和符号中已经存在的变量名是否冲突,对不合法或者冲突的键名将会根据此参数的设定的规则来决定。
- EXTR_OVERWRITE - 默认。如果有冲突,则覆盖已有的变量。
- EXTR_SKIP - 如果有冲突,不覆盖已有的变量。
- EXTR_PREFIX_SAME - 如果有冲突,在变量名前加上前缀 prefix。
- EXTR_PREFIX_ALL - 给所有变量名加上前缀 prefix。
- EXTR_PREFIX_INVALID - 仅在不合法或数字变量名前加上前缀 prefix。
- EXTR_IF_EXISTS - 仅在当前符号表中已有同名变量时,覆盖它们的值。其它的都不处理。
- EXTR_PREFIX_IF_EXISTS - 仅在当前符号表中已有同名变量时,建立附加了前缀的变量名,其它的都不处理。
- EXTR_REFS - 将变量作为引用提取。导入的变量仍然引用了数组参数的值。
- prefix:可选。如果 extract_rules 参数的值是 EXTR_PREFIX_SAME、EXTR_PREFIX_ALL、 EXTR_PREFIX_INVALID 或 EXTR_PREFIX_IF_EXISTS,则 prefix 是必需的。
代码示例:
1 |
|
参时如果我们POST传入name=dog,那么页面将会回显dog,说明这个函数的使用让我们实现了变量的覆盖,改变了变量的值。
parse_str()
此函数把查询到的字符串解析到变量中。
1 | parse_str(string,array) |
参数
- string:必需。规定要解析的字符串。
- array:可选。规定存储变量的数组名称。该参数只是变量存储到数组中。代码示例:
代码示例:
1 |
|
通过上述代码,我们可以发现,变量name和age都发生了变化,被新的值覆盖了。这里我用的是 PHP 7.4.3 版本。发现这个函数的这个作用还是存在的,且没有任何危险提示。
import_request_variables()
此函数将GET/POST/Cookie变量导入到全局作用域中。从而能够达到变量覆盖的作用。
版本要求:PHP 4 >= 4.1.0, PHP 5 < 5.4.0
1 | bool import_request_variables ( string $types [, string $prefix ] ) |
参数
- types:指定需要导入的变量,可以用字母 G、P 和 C 分别表示 GET、POST 和 Cookie,这些字母不区分大小写,所以你可以使用 g 、 p 和 c 的任何组合。POST 包含了通过 POST 方法上传的文件信息。注意这些字母的顺序,当使用 gp 时,POST 变量将使用相同的名字覆盖 GET 变量。
- prefix:变量名的前缀,置于所有被导入到全局作用域的变量之前。所以如果你有个名为 userid 的 GET 变量,同时提供了 pref_ 作为前缀,那么你将获得一个名为 $pref_userid 的全局变量。虽然 prefix 参数是可选的,但如果不指定前缀,或者指定一个空字符串作为前缀,你将获得一个 E_NOTICE 级别的错误。
代码示例:
1 |
|
如果什么变量也不传,那么页面将回显You are not Ameng如果通过GET或者POST传入name=Ameng那么页面就会回显Ameng
可以见到此函数还是很危险的,没有修复方法,不使用就是最好的方法。所以在新版本的 PHP 中已经废弃了这个函数。
foreach()
foreach 语法结构提供了遍历数组的简单方式。foreach 仅能够应用于数组和对象,如果尝试应用于其他数据类型的变量,或者未初始化的变量将发出错误信息。有两种语法:
1 | foreach (array_expression as $value) |
第一种格式遍历给定的 array_expression 数组。每次循环中,当前单元的值被赋给 $value 并且数组内部的指针向前移一步(因此下一次循环中将会得到下一个单元)。
第二种格式做同样的事,只是除了当前单元的键名也会在每次循环中被赋给变量 $key。
那么这个函数如何实现变量的覆盖呢?我们来看个案例.
代码示例:
1 |
|
那么执行结果是怎样的呢?当我们直接打开页面的时候它会输出You are false!,而当我们通过GET传参name=Ameng的时候,它会回显You are right!。那么这是为什么呢?我们来分析一下
关键点就在于$$这种写法。这种写法称为可变变量。一个变量能够获取一个普通变量的值作为这个可变变量的变量名。当使用foreach来遍历数组中的值,然后再将获取到的数组键名作为变量,数组中的键值作为变量的值。这样就产生了变量覆盖漏洞,如上代码示例。其执行过程为$$key=$name,最后赋值为$value,从而实现了变量覆盖。
弱类型比较
md5()函数和sha1()绕过
关于这两个函数想必我们不陌生,无论是在实际代码审计中,还是在CTF比赛中,这些我们都是碰到过的函数。那么当我们遇到用这两个函数来判断的时候,如果绕过呢?
PHP 在处理哈希字符串的时候,会使用!=或者==来对哈希值进行比较,它会把每一个0E开头的哈希值都解释为0,那么这个时候问题就来了,如果两个不同的值,经过哈希以后它们都变成了0E开头的哈希值,那么 PHP 就会将它们视作相等处理。那么0E开头的哈希值有哪些呢?
1 | s878926199a |
来个简单的例子吧
代码示例:
1 |
|
从上面我给出的哪些值中,挑两个不同的值传入参数,就能看到相应的结果
上面是md5()函数的绕过姿势,那么sha1()如何绕过呢?再来看一个简单的例子
1 |
|
当我们传入a[]=1&b[]=2的时候,虽然它会给出警告,说我们应该传入字符串而不应该是数组,但是它还是输出了nice!!!,所以我们完全可以用数字来绕过sha1()函数的比较。
is_numeric()绕过
我们先来了解一下这个函数。此函数是检测变量是否为数字或者数字字符串
1 | is_numeric( mixed $var) : bool |
如果var是数字或者数字字符串那么就返回TRUE,否则就返回FALSE。那么这里说的绕过是什么姿势呢?是十六进制。我们先来看一个简单的例子。
代码示例:
1 |
|
这里说一下0x31206f722031这个是什么?这个是or 1=1的十六进制,从这里可以看出,如果某处使用了此函数,并将修饰后的变量带入数据库查询语句中,那么我们就能利用此漏洞实现sql注入。同样的,这个漏洞再CTF比赛中也是很常见的。
in_array()绕过
此函数用来检测数组中是否存在某个值。
1 | in_array( mixed $needle, array $haystack[, bool $strict = FALSE] ) : bool |
参数
- needle:带搜索的值(区分大小写)。
- haystack:带搜索的数组。
- strict:若此参数的值为TRUE,那么
in_array()函数将会检查needle的类型是否和haystack中的类型相同。
有时候我们再传入一个数组的时候,代码可能会过滤某些敏感字符串,但是我们又需要传入这样的字符串,那么我们应该如何绕过它的检测呢?
1 |
|
上面代码示例执行的结果会是什么呢?从简单的逻辑上分析。0是不存在要搜索的数组中的,所以理论上,应该是输出not in array,但是实际却输出了It's in array。这是为什么呢?原因就在于PHP的默认类型转换。这里我们第三个参数并没有设置为true那么默认就是非严格比较,所以在数字与字符串进行比较时,字符串先被强制转换成数字,然后再进行比较。并且因为某些类型转换正在发生,就会导致发生数据丢失,并且都被视为相同。所以归根到底还是非严格比较导致的问题。所以再遇到这个函数用来变量检测的时候,我们可以看看第三个参数是否开启,若未开启,则存在数组绕过。
XSS
print()
代码示例:
1 |
|
echo()
代码示例:
1 |
|
printf()
代码示例:
1 |
|
sprintf()
代码示例:
1 |
|
die()
此函数输出一条信息,并退出当前脚本。
代码示例:
1 |
|
var_dump()
此函数打印变量的相关信息,用来显示关于一个或多个表达式的结构信息,包括表达式的类型与值。数组将递归展开之,通过缩进显示其结构。
代码示例:
1 |
|
var_export()
此函数输出或者返回一个变量的字符串表示。它返回关于传递给该函数的变量的结构信息,和var_dump类似,不同的是其返回的表示是合法的 PHP 代码。
代码示例:
1 |
|
PHP黑魔法
md5()
md5()函数绕过sql注入。我们来看一个例子。
代码示例:
1 | $password=$_POST['password']; |
这里提交的参数通过md5函数处理,然后再进入SQL查询语句,所以常规的注入手段就不行了,那么如果md5后的转换成字符串格式变成了'or'xxxx的格式,不就可以注入了么。md5(ffifdyop,32) = 276f722736c95d99e921722cf9ed621c
转成字符串为'or'6xxx
eval()
在执行命令时,可使用分号构造处多条语句。类似这种。
1 |
|
ereg()
存在%00截断,当遇到使用此函数来进行正则匹配时,我们可以用%00来截断正则匹配,从而绕过正则。
strcmp()
这个在前面介绍过,就是数组绕过技巧。
curl_setopt()
存在ssrf漏洞。
代码示例:
1 |
|
preg_replace()
此函数前面详细介绍过,/e模式下的命令执行。
urldecode()
url二次编码绕过。
代码示例:
1 |
|
将Ameng进行二次url编码,然后传入即可得到满足条件。
file_get_contents()
常用伪协议来进行绕过。
parse_url()
此函数主要用于绕过某些过滤,先简单了解一下函数的基本用法。
代码示例:
1 |
|
可以看到这个函数把我们的变量值拆分成一个几个部分。那么绕过过滤又是说的哪回事呢?其实就是当我们在浏览器输入url时,那么就会将url中的\转换为/,从而就会导致parse_url的白名单绕过。
反序列化漏洞
在了解一些函数之前,我们首先需要了解什么是序列化和反序列化。
序列化:把对象转换为字节序列的过程成为对象的序列化。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
归根到底,就是将数据转化成一种可逆的数据结构,逆向的过程就是反序列化。
在 PHP 中主要就是通过serialize和unserialize来实现数据的序列化和反序列化。
那么漏洞是如何形成的呢?
PHP 的反序列化漏洞主要是因为未对用户输入的序列化字符串进行检测,导致攻击者可以控制反序列化的过程,从而就可以导致各种危险行为。
那么我们先来看一看序列化后的数据格式是怎样的,了解了序列化后的数据,我们才能更好的理解和利用漏洞。所以我们来构造一段序列化的值。
代码示例:
1 |
|
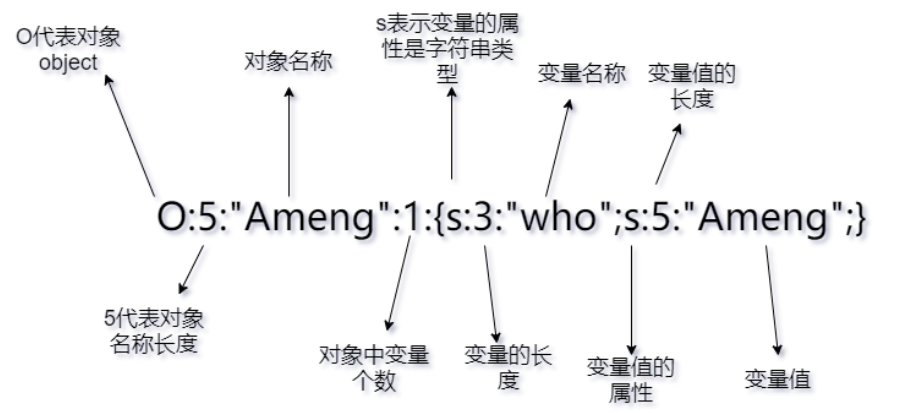
这里还要补充一点,就是关于变量的分类,变量的类别有三种:
- public:正常操作,在反序列化时原型就行。
- protected:反序列化时在变量名前加上%00*%00。
- private:反序列化时在变量名前加上%00类名%00。
__wakeup()
在我们反序列化时,会先检查类中是否存在__wakeup()如果存在,则执行。但是如果对象属性个数的值大于真实的属性个数时就会跳过__wakeup()执行__destruct()。
影响版本:
PHP5 < 5.6.25
PHP7 < 7.0.10
代码示例:
1 |
|
__sleep()
__sleep()函数刚好与__waeup()相反,前者是在序列化一个对象时被调用,后者是在反序列化时被调用。那么该如何利用呢?我们看看代码。
1 |
|
__destruct()
这个函数的作用其实在上面的例子中已经显示了,就是在对象被销毁时调用,倘若这个函数中有命令执行之类的功能,我们完全可以利用这一点来进行漏洞的利用,得到自己想要的结果。
__construct()
这个函数的作用在__sleep()也是体现了的,这个函数就是在一个对象被创建时会调用这个函数,比如我在__sleep()中用这个函数来对变量进行赋值。
__call()
此函数用来监视一个对象中的其他方法。当你尝试调用一个对象中不存在的或者被权限控制的方法,那么__call就会被自动调用
代码示例:
1 |
|
__callStatic()
这个方法是 PHP5.3 增加的新方法。主要是调用不可见的静态方法时会自动调用。具体使用在上面代码示例和结果可见。那么这两个函数有什么值得我们关注的呢?想一想,倘若这两个函数中有命令执行的函数,那么我们调用对象中不存在方法时就可以调用这两个函数,这不就达到我们想要的目的了。
__get()
一般来说,我们总是把类的属性定义为private。但有时候我们对属性的读取和赋值是非常频繁,这个时候PHP就提供了两个函数来获取和赋值类中的属性。
get方法用来获取私有成员属性的值。
代码示例:
1 | //__get()方法用来获取私有属性 |
参数
- $name:要获取成员属性的名称。
__set()
此方法用来给私有成员属性赋值。
代码示例:
1 | //__set()方法用来设置私有属性 |
参数
- $name:要赋值的属性名。
- $value:给属性赋值的值。
__isset()
这个函数是当我们对不可访问属性调用isset()或者empty()时调用。
在这之前我们要先了解一下isset()函数的使用。isset()函数检测某个变量是否被设置了。所以这个时候问题就来了,如果我们使用这个函数去检测对象里面的成员是否设定,那么会发生什么呢?
若对象的成员是公有成员,那没什么问题。倘若对象的成员是私有成员,那这个函数就不行了,人家根本就不允许你访问,你咋能检测人家是否设定了呢?那我们该怎么办?这个时候我们可以在类里面加上__isset()方法,接下来就可以使用isset()在对象外面访问对象里面的私有成员了。
代码示例:
1 |
|
__unset()
这个方法基本和__insset情况一致,都是在类外访问类内私有成员时要调用这个函数,基本调用的方法和上面一致。
代码示例:
1 |
|
toString()
此函数是将一个对象当作一个字符串来使用时,就会自动调用该方法,且在该方法中,可以返回一定的字符串,来表示该对象转换为字符串之后的结果。
通常情况下,我们访问类的属性的时候都是$实例化名称->属性名这样的格式去访问,但是我们不能直接echo去输出对象,可是当我们使用__tostring()就可以直接用echo来输出了。
代码示例:
1 |
|
执行结果:
1 | Ameng3岁了 |
__invoke()
当尝试以调用函数的方式调用一个对象时,__invoke()方法会被自动调用。
版本要求:
PHP > 5.3.0
代码示例:
1 |
|
pop链的构造
思路
- 寻找位点(unserialize函数—>变量可控)
- 正向构造(各种方法)
- 反向推理(从要完成的目的出发,反向推理,最后找到最先被调用的位置处)
来看一个简单的例子(HECTF):
1 |
|
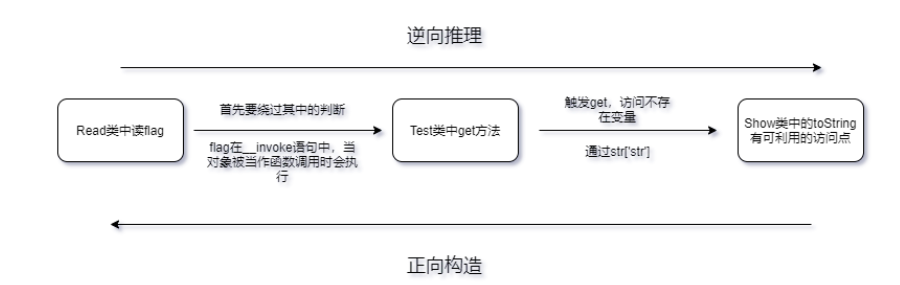
我们要拿到flag,在__invoke()函数,当对象被当作函数调用时,那么就会自动执行该函数。所以我们要做的就是用函数来调用对象。
那么我们首先找到起点,就是unserialize函数的变量,因为这个变量是我们可控的,但是肯定是过滤了一些常见的协议,那些协议我在上面也简单介绍过用法。
通过函数的过程搜索,我们能够看到preg_match第二个参数会被当作字符串处理,在类Test中,我们可以给$func赋值给Read对象。
那么我们可以构造如下pop链
1 |
|
给个图总结一下:
phar与反序列化
简介
PHAR(”PHP archive”)是PHP里类似JAR的一种打包文件,在PHP > 5.3版本中默认开启。其实就是用来打包程序的。
文件结构
a stub:
xxx<?php xxx;__HALT_COMPILER();?>前面内容不限,后面必须以__HALT_COMPILER();?>结尾,否则phar扩展无法将该文件识别为phar文件。官方手册
phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都放在这部分。这部分还会以序列化的形式存储用户自定义的meta-data,这是上述攻击手法最核心的地方。
实验
前提:将php.ini中的phar.readonly选项设置为off,不然无法生成phar文件。
phar.php:
1 |
|
在我们访问之后,会在当前目录下生成一个phar.phar文件。
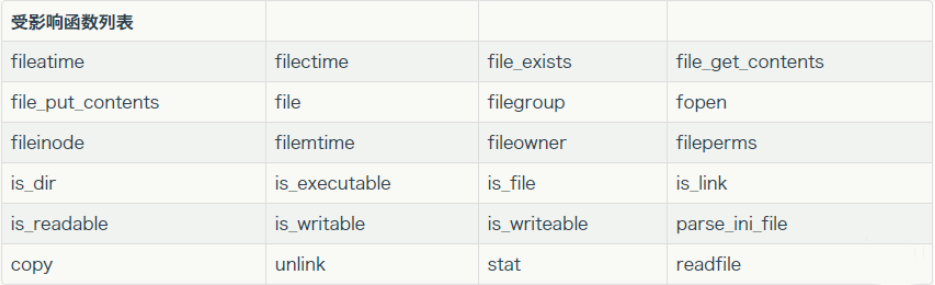
然后查看文件的十六进制形式,我们就可以看到meta-data是以序列化的形式存储。既然存在序列化的数据,那肯定有序列化的逆向操作反序列化。那么这里在PHP中存在很多通过phar://伪协议解析phar文件时,会将meta-data进行反序列化。可用函数如下图
Ameng.php
1 |
|
其他一些总结
basename()
此函数返回路径中的文件名的一部分(后面)
1 | basename(path,suffix) |
参数
- path:必需。规定要检查的路径。
- suffix:可选。规定文件的扩展名。
代码示例:
1 |
|
此函数还有一个特点,就是会去掉文件名的非ASCII码值。
代码示例:
1 |
|
可以看到,%ff直接没了,而是直接输出前面的的文件名,这个可以用来绕过一些正则匹配。原因就在于%ff在通过 url 传参时会被 url 解码,解码成了不可见字符,满足了basename函数对文件名的非ASCII值去除的特点,从而被删掉。
参考链接:https://wiki.wgpsec.org/knowledge/code-audit/php-code-audit.html(狼组知识库)